Posted by bert hubert
Sat, 24 May 2008 08:37:00 GMT
18th of May, Delft, The Netherlands
Mirjam & Bert are proud to announce the birth of their son Maurits Hubert! Mother, son & father are doing very well.
Feel free to email the little guy on maurits@hubertnet.nl!
Picture when Maurits was only an hour old:

And a slightly geeky Droste Effect photo:

Posted in Life | no comments
Posted by bert hubert
Tue, 13 Nov 2007 12:42:00 GMT
Exactly one year ago today, my father passed away, less than a year after my mother did.
Here you can see them in happier times, together with the other subject of this post:

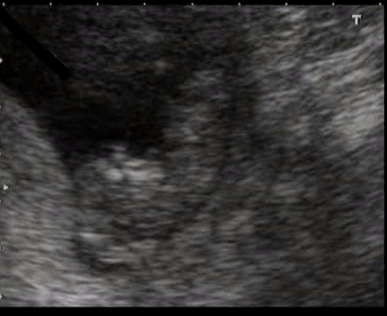
While we mourn their passing today, not all news is bad. I’m happy to announce Mirjam and I are expecting a baby!
We’re very happy, but sad we won’t be able to share the good news with my parents. But: life goes on - which is literally true in this case.
Bert & Mirjam
Posted in Life | 3 comments
Posted by bert hubert
Wed, 21 Feb 2007 22:13:00 GMT

Enjoyed a fun and stimulating “DNS & Crypto Power Lunch” with Dan Bernstein (left) and Tanja Lange (not in picture). As was to be expected, the intersection of cryptography and (secure) DNS was discussed, and some evil plans might ensue! If implemented in djbdns and PowerDNS, we might actually achieve something..
Posted in PowerDNS, Netherlabs, Life | no comments
Posted by bert hubert
Sun, 04 Feb 2007 12:14:00 GMT
Ok, I’m going to lecture a bit, a bad habit of mine. The summary is that an important enhancement of the Linux kernel has been proposed, but in order to understand the significance of this enhancement, you need a lot of theory, which follows below.
I use the word “computer” sometimes when I properly mean “the operating system”. This exposes a problem of this post, I’m trying to explain something deeply theoretical to a general audience. Perhaps it didn’t work. See for yourself.
Doing many things at once
People generally tend not to be very good at doing many thing at once, and surprisingly, computers are not much different in this respect.
First about human beings. We can do one thing at a time, reasonably well. There are people that claim they can multi-task, but if you look into it, that generally means doing one thing that is really simple, while simultaneously talking on the phone.
This is exemplified by how we answer a second phone call, ie, by saying “The other line is ringing, I’ll call you back”, or conversely, telling the other line they’ll have to wait.
We emphatically don’t try to have two conversations at once, and even if we had two mouths, we still wouldn’t attempt it.
Let’s take a look at a web server, the program that makes web pages available to internet browsers. The basic steps are:
- Wait for new connections from the internet
- Once a new connection is in, read from it which page it wants to see (for example, ‘GET http://blog.netherlabs.nl/ HTTP/1.1’).
- Find that page in the computer
- Send it to the web browser that connected to us
- Go to 1.
Compare this to answering a phone call, step 1 is the part where you wait for the phone to ring, and answering it when it does. Step 2 is hearing what the caller wants, step 3 is figuring out the answer to the query, 4 is sharing that answer.
This all seems natural to us, as it is the way we think. And programmers, contrary to what people think, are human beings, too.
Where this simple process breaks down is that, much like a regular phone call, we can only serve a new web page once the old one is done sending.
And here is where things get interesting - although we people have a hard time doing multiple things at once, we can give the problem to the computer.
What is the easiest way of doing so? Well, if we want to increase the capacity of a telephone service we do so.. by adding people. So on the programming side of things, we do the same thing, only virtually: we order the computer (or more exactly, the operating system) to split itself in two!
The new list of steps now becomes:
- Wait for new connections from the internet
- Once a new connection is in, split the computer in two.
- One half of the computer goes back to step 1, the other half continues this list
- (2) Read from it which page it wants to see (for example, ‘GET http://blog.netherlabs.nl/ HTTP/1.1’).
- (2) Find that page
- (2) Send it to the web browser
- (2) Done - remove this “half” of the computer
I’ve prefixed the things the second computer does with ”(2)” . This looks like the best of both worlds. We can “serve” many web pages at the same time, and we didn’t need to do complicated things. In other words, we could continue thinking like human beings, and use our intuition, by thinking of the analogies with answering phone calls.
So, are we done now? Sadly no. What basically has happened is that we have invoked a piece of magic: let’s split the computer in two. That is all fine, but somebody has to do the splitting. This job is farmed out to the CPU (the processor) and the operating system (Windows, Linux etc), and they have to deal with making sure it appears the computer can do two things at the same time.
Because the truth is.. people can’t do it, and neither can computers. They fake it.
This faking comes at a cost, incurred both while splitting the computer (“forking”), and by making the computer juggle all its separate parts. Finally, it turns out that practically speaking, you can divide a computer up into only a limited number of parts before the charade falls down.
Busy websites have tens of millions of visitors, we’d need to be able to split the computer into at least that many parts, while in practice the limit lies at perhaps 100,000 slices, if not less.
Now what
Several solutions to this problem have been invented. Some involve not quite splitting up the entire computer and making split parts share more of the resources (like for example, memory). This is called ‘threading’. Perhaps this could be compared with not hiring more people to answer the telephone, but instead giving the people you have more heads, so as to save money.
In the end, all these solutions run into a brick wall: it is hard to maintain the illusion that the computer can do multiple things at the same time, AND have it actually do a million things at the same time.
So in the end, we have to bite the bullet, and just make sure the program itself can handle many many things at once, without needing the magic of pretending the computer can do it for us.
“Asynchronous programming”
This is where things get hard, and this is to be expected, as it was our basic premise that people can’t do multiple things at the same time, and what’s worse, they have a hard time even thinking about what it would be like.
The new algorithm looks like this:
- Instruct the computer to tell us when “something has happened”
- Figure out what happened:
- If there is a new connection, instruct the computer that from now on, it should tell us if new data arrived on that connection
- If something has happened to one of those connections we’ve told the computer about, read the data sent to us on that connection. Then find the information requested on that connection, and instruct the computer to tell us when there is “room” to send that data
- If the computer told us there was “room”, send the data that was previously requested on that connection. If we are done sending all the data, tell the computer to disconnect, and no longer inform us of the state of the connection.
- Go back to 1.
If this feels complicated, you’d be right. However, this is how all very high performance computer applications work, because the “faking” described above doesn’t really “scale” to tens of thousands of connections.
How does this translate to the telephone situation? It would be like we have lots of small answering machines, that lots of callers can talk to at the same time. Whenever someone has finished a question, the operator would listen to that answering machine, and leave the answer on the machine, and go on to the next machine that has a finished message.
From this description, it is clear it would not work faster that way if you’d try it for real. However, in many countries, if you call a directory service to find a telephone number, you’ll get half of this. Your call is answered by a real human being, who asks you questions to figure out which phone number you are looking for. But once it has been found, the operator presses a button, and the result of your query is sent to a computer, which then reads it to you, allowing the operator to already start answering a new call. Rather smart.
Something in between
If the previous bit was hard to understand, I make no apologies, this is just how complicated things are in the world of computing. However, we programmers also hate to deal with complicated things, so we try to avoid stuff like this.
People have invented many ways of allowing programmers to think ‘linearly’, as if only a single thing is happening at the same time, without having to split the entire computer.
One way of doing this is having a facade that makes things go linearly, until the program has to wait for something (a new connection, “room” to send data etc), and then switch over to processing another connection. Once that connection has to wait for something, chances are that what our earlier ‘wait’ was waiting for has happened, and that program can continue.
This truly offers us the best of both worlds: we can program as if only a single thing is happening at the same time, something we are used to, but the moment the computer has to wait for something, we are switched automatically to another part of the program, that is also written as if it is the only thing happening at the same time.
Actually making this happen is pretty hard however, because traditional computer programming environments don’t clearly separate actions that could lead to “waiting” from actions that should happen instantly.
A prime example of the first kind of action is “waiting for a new connection” - this might in theory take forever, especially if your website is really unpopular.
Things that should happen instantly include for example asking the computer what time it thinks it is.
Traditional operating systems can be instructed to be mindful of new incoming connections, and not keep the program waiting for them. This is what we described in the complicated “if X happened, if Y happened” scenario above.
They can also do the same for reading from the network and writing to the network, both things that might take time. This means you can ask the operating system ‘let me know when I can read so I don’t have to wait for it, and I can process other connections in the meantime’.
Furthermore, there are some limited tricks to do the same for reading a file. The problem is that back in the 1970s when most operating system theory was being invented, disks were considered so fast, nobody thought it possible you’d ever need to meaningfully wait for one. Of course disks weren’t faster back then, but computers were slower, and massively so. So by comparison, disks were really fast.
The upshot is that in most operating systems, disk reads are grouped with “stuff that should happen instantly”, whereas every computer user by now has experienced this is emphatically not the case.
Modern operating systems offer only a limited solution to this problem, called ‘asynchronous input/output’, which allows one to more or less tell the computer to notify us when it has read a certain piece of data from disk.
However, it doesn’t offer the same facility for doing a lot of other things that might take time, like finding the file in the first place, or opening it. Things that in the real world take a lot of time.
So, we can’t truly enjoy the best of both worlds as sketched above, which would mean the programmer could write simple programs, which would be switched every time his program has to wait for something.
Enter ‘Generic AIO’
Zach Brown, who is employed by Oracle to work on Linux, has now dreamed up something that appears to never have been done before: everything can now be considered something that “might take time”.
This means that you can ask Linux to find a certain file for you, and immediately allows you to process other connections that need attention. Once the operating system has found the file for you, it is available for you without waiting.
Although almost every advance in operating system design has at one point been researched already, this approach appears to be rather revolutionary.
It has ignited vigorous discussion within the Linux community about the feasibility of this approach, and if it truly is the dreamt of “best of both worlds”, but to this author, it surely looks like a breakthrough.
Especially since it unites the worlds of “waiting on a read/write from the network” with “waiting for a file to be read from disk”.
Time will tell if “Generic AIO” will become part of Linux. In the meantime, you can read more about it on LWN.
Posted in Linux, Netherlabs, Life | 2 comments
Posted by bert hubert
Fri, 12 Jan 2007 21:16:00 GMT
The workings of the Internet are described, or even proscribed, by the so called ‘Requests For Comments’, or RFCs. These are the laws of the internet.
Today the IETF DNS Extensions working group accepted an “Internet-Draft” Remco van Mook and I have been working on. And the cool bit is that over time, many such accepted “Internet-Drafts” turn into RFCs!
Read about it what our draft does
here
and here.
The actual Internet-Draft can be found over at the IETF, or over here as pretty HTML.
In short, this RFC documents and standardises some of the stuff DJBDNS and PowerDNS have been doing to make the DNS a safer place.
Besides the fact that it is important to update the DNS standards to reflect this practice, it is also rather a cool thought to actually be writing an RFC, especially one that has the magic stanzas “Standards Track” and “Updates 1035” in it.
So we are well pleased! Over the coming months we’ll have to tune the draft so it confirms with the consensus of the DNSEXT working group, and hopefull somewhere around March, it will head towards the IESG, after which an actual RFC should be issued.
Exciting!
Posted in Linux, PowerDNS, Netherlabs, Life | 10 comments
Posted by bert hubert
Mon, 01 Jan 2007 15:58:00 GMT
I wish everybody a very good 2007! For PowerDNS, it certainly has been a very good year.
In some (large) places, the Recursor now commands a 40% market share, while the authoritative server is also expanding its user base around the world, with multi-million domain deployments now no longer as newsworthy as they once were.
The Chaos Computer Club held its annual congress last week, and they chose the PowerDNS Recursor to provide the DNS service to go with their 10 gigabit connection. I’m pleased to report that the PowerDNS process was fired up only once, and that it held steady for the entire congress, with no complaints. This would usually not be that strange, but the CCC clientèle are among the most critical internet users to be found on the planet.
Many thanks to Stefan Schmidt and other CCC admins for their vote of confidence!
Rails
I’m working on understanding ‘Ruby on Rails’, which will probably end up as a HOWTO aimed at seasoned programmers. The internet abounds with “you won’t believe how easy Ruby on Rails is” demonstrations, but the hard truth is that below the surface, a lot of magic is happening. The kind of magic the discerning programmer wants to grasp so as to make the most of it.
A very small start to this HOWTO can be found here.
It may also allow experience programmers to teach themselves Ruby in less time than it would take them to read a 750 page book.
Posted in Linux, PowerDNS, Netherlabs, Life | 7 comments
Posted by bert hubert
Fri, 24 Nov 2006 21:55:00 GMT
Yesterday I visited a “software development seminar” of ASML, a rather well disguised recruiting event of this Dutch manufacturer of the world’s most advanced lithography machines.
When I studied physics, I organized the Delftse Bedrijvendagen, the then largest carreer fair for university students of The Netherlands. As part of that, I was exposed to almost all recruiters of large Dutch companies, including ASML. And the ASML people never failed to leave me light headed.
In brief, lithography is a major piece of the process of actually making chips. It is the part where you actually put the chip on the substrate, using high energy photons. Current 65nm chips consist of many layers, each of these layers needs to be overlaid with the previous one to a precision of a few nanometres.
To achieve this precision, the individual positioning tolerances of the wafer need to be exact within a nanometre. This is a stunning achievement in itself. For those of you in the non-metric world, there are around 25 million nanometres to an inch. So you should be impressed.
However, this is nothing yet. The lithography machines (‘wafer steppers’) are very expensive, as is the facility that hosts them. And, as there are many layers in a chip, the actual speed of the wafer stepper is of utmost importance.
The machines ASML builds actually illuminate the ‘reticle’ at speeds exceeding 5 metres a second. This is 11 miles/hour. At nanometre precision.
You should have progressed beyond “impressed” to “stunned” by now.
But this is nothing yet. As in microscopy, where water is used to improve resolution, it makes sense to immerse your chip in water while it is being exposed. So the ASML people do that. At nanometre precisions, at those stunning speeds.
To put things in perspective, the wafer is NOT flat to within a nanometre, it bends a bit. So to achieve the precision desired, the wafer is first scanned, so all its imprecisions can be compensated for.
Extreme stuff. I’m sure they don’t have this in “Star Trek”.
I left the event deeply confused - I’m already completely busy with everything I do, and PowerDNS is getting to be quite the empire. The rest of my business is doing great as well.
But my physics background makes me appreciate the incredible things happening over at ASML. Oh well. Like any job, I’m sure it would have downsides. Also, I’m not the kind of person to hold a regular job. But if you want to do stuff on the leading edge of technology, you should at least consider working there. I hear they have 300 vacancies planned for software engineers. They also have some blogs, by the way.
Their current challenge is to move their 15 million lines of C to a new platform that will control their next generation of devices, some of which need to move terabyte amounts of data in under a second.
Anyhow, the seminar was interesting. Tom Gilb presented his “Evolutionary Project Management” concepts, which match rather well with how I tend to manage my projects. One of his main points is that when people start to apply “waterfall” diagrams to software projects, you are lost anyhow. I thought so all along, but it is nice to hear a “guru” confirm it.
Inspired by the breakthrough technologies over at ASML, I’ve picked up my own speech recognition research again, after an 18 month hiatus. The initial results bode well. I get very good frequency and time definition on real speech, with code totalling 750 lines. I hope to get some actual recognition going in the coming week.
Posted in PowerDNS, Netherlabs, Life | 9 comments
Posted by bert hubert
Thu, 23 Nov 2006 10:02:00 GMT
Within the last 12 months, both of my parents have passed away, both after prolonged illness. Here you can see them in happier times a few years ago.
We’ll miss them terribly.
Posted in Life | 5 comments
Posted by bert hubert
Fri, 06 Oct 2006 22:52:00 GMT
Well, I reported previously that the server that powers this blog fell 9 feet, and appeared to have survived? Since that event, one of the disks reported odd errors every once in a while, but those appeared to point to a bad cable. I replaced it, but no joy, problems remained.
So tonight I decide to back up that disk completely, and take it out of use. And lo, during the backup it decides to pack up! It made a noise like a passing moped, and ceased to work. Backup was almost entirely done.
I restored the backup to another computer and mounted it via NFS (over wifi no less!), and things (including this blog) are back in production again. I’ll have to buy new disks ASAP though.
PowerDNS RIPE presentation
RIPE was lots of fun, although my presentation did not go as well as I’d hoped. I’ve been distracted by grave medical problems in my family, which mean that I spend a lot of my time in the hospital. It might’ve been better to not do the presentation. Some people did tell me they enjoyed it though. Oh well.
For the first time, I’ve had the pleasure of answering a question from a webcam viewer! RIPE offers the great service that remote attendants can ask questions over IRC or Jabber, and a RIPE employee will then relay the question. A tremendous service!
Lunch at RIPE was fantastic, and it was very nice to meet many friends again. All in all a good day.
Posted in Linux, PowerDNS, Life | 7 comments
Posted by bert hubert
Thu, 21 Sep 2006 21:16:00 GMT
Quick update on some small things.
PowerDNS
I managed to release PowerDNS Recursor 3.1.3 which must rank as one of the most succesful releases of PowerDNS ever, as I have had zero feedback, despite a large number of downloads. Most big deployments have switched over. There is still a very small trickle of odd crashes though, but they are so rare it is hard to pin it down to anything.
Wireless
Our new house has a lot going for it, except wiring possibilities. It might be possible to improve this, but right now I want nothing but the best and I’m not prepared to soil my house with badly laid cables. So it has to be wireless, which for fixed computers mostly means USB. After some searching and experimenting, I can report that zd1211 derived devices work really well using the Linux zd1211rw driver. Wireless reception depends a lot on RF conditions, having a USB receiver on a cable means you can move it around for the best reception.
The nice thing about the ZD1211 derived devices (I have two 3Com OfficeConnect adaptors) is that the authors of the driver are very approachable and work well with (and are in fact part of) the Linux kernel community. Unlike some.
New house
It still rocks, although we haven’t had much time to empty the last boxes and buy furniture that matches the quality of the house. Sadly, we are spending a lot of time in the hospital and taking care of related things.
Posted in Linux, PowerDNS, Netherlabs, Life | 9 comments
